Introdução ao RDF: Resource
Description FrameworkPublicação e
Recuperação de Projetos de Pesquisas
Universidade
Federal do Rio Grande do Sul
Por
Nelson Henrique Zanete – [email protected]
Mestrando em Ciência da
Computação
Prof.: José Valdeni de Lima
Resumo
O Resource
Description Framework (RDF) é uma infra-estrutura, que possibilita a
codificação, troca e reuso de estruturas de meta-dados. [5] RDF permite uma visão complementar dos dados, através do uso de mecanismos que suportam convenções comuns
de semântica, sintaxe e estrutura.
Muitas instituições de pesquisas deixam de oferecer de forma eficiente a principal matéria-prima para o desenvolvimento sócioeconômico na era da globalização: a informação. Pelo menos
três aspectos importantes, contribuem para o propósito de informar: A
integração institucional, a multidisciplinaridade e a aprendizagem a partir do
enfrentamento de problemas do cotidiano com informações rápidas e precisas. Nesse
artigo, abordamos alguns problemas de semântica
para descrever recursos da as
instituições de pesquisa, que retardam o acesso e a difusão das informações
científicas necessárias a este propósito Web e sugerimos
soluções tecnológicas viáveis para minimizá-los. A idéia
básica, consiste na utilização
marcações apropriadas para cada elemento de um
projeto de pesquisa e utilizar recursos e tecnologias apropriadas para processamento, difusão e recuperação das informações.
A idéia básica, consiste na adição de Meta-dados, (dados sobre
os dados) afim de
descrever conteúdos, direitos autorais ou até mesmo representar
conhecimento, com algum mecanismo de argumentação (reasoning) dos recursos da Web. -
1. Introdução
Hoje em dia as informações científicas mais
recentes, se encontram distribuídas no ambiente World Wide Web. A descoberta e
a troca de informações entre comunidades é um processo difícil, devido a falta
de padrões entre os termos e vocabulários diferenciados
de
cada comunidade
Hoje em dia as informações científicas mais
recentes, se encontram no ambiente World Wide Web. O acesso aos recursos se tornaram tão comuns que já
são realidade nas diversas instituições de pesquisa. O correio eletrônico, os sistemas de procura de
informações, os grupos de discussões e as interfaces amigáveis dos navegadores,
constituem poderosas ferramentas para busca do conhecimento. Em todo o mundo,
uma grande quantidade de informações de pesquisas, tem sido publicada na World
Wide Web num
formato conhecido como HTML (Hypertext Markup Language). Este formato descreve
como os navegadores devem apresentar o texto referente a este documento. A
abordagem do HTML inibe um aspecto importante da publicação de informações, que
é torná-las acessíveis. Enquanto ele se preocupa com a forma de apresentação dos dados, deixa de lado o aspecto mais
importante, que é o significado dos dados. Nossa
principal motivação é apresentar um estudo de
caso real, da
complexidade das informações contidas nos projetos de pesquisas
e propor uma solução viável para publicação e acesso
a estas informações. O Artigo está
organizado como segue: Seção 2 apresenta a instituição que foi realizado o
estudo de caso e qual o objetivo do projeto. A seção 3 apresenta a estrutura das informações contidas nos projetos
de pesquisa. A seção 4 comenta os
problemas com a abordagem HTML, normalmente
utilizada para publicação destas informações e apresenta
uma nova proposta. A seção 5
apresenta as considerações finais com algumas sugestões adicionais.
PALAVRAS CHAVES: Projetos de Pesquisa,
Publicação, Documentos Estruturados, Competitividade, Difusão de
tecnologia.
A Instituição
O presente
estudo de caso foi realizado no Instituto Agronômico do Paraná - IAPAR que é
uma instituição de pesquisa agropecuária cuja missão é gerar e difundir
conhecimentos científicos e tecnológicos para o desenvolvimento sustentado da
agropecuária paranaense. As pesquisas do IAPAR resultaram em variedades
melhoradas, definição de tecnologias adequadas e a atuação em programas
voltados para desenvolvimento sustentado da agropecuária paranaense. Desde sua fundação o IAPAR produziu uma grande quantidade de informações que
foram se acumulando com o passar do
tempo, em caixas de papéis cheias de documentos, relatórios
técnicos e resultados de pesquisas. O objetivo deste projeto é tratar o
grande volume de informações geradas por mais de vinte anos de pesquisas, a fim
de que possa, eficientemente, ser disponibilizadas para comunidade científica.
A estrutura das Informações
. Devido aos
variados tipos de informações como textos,
tabelas, imagens, fórmulas matemáticas, fórmulas químicas e outras, o meio para descrever cada recurso
deste tipo, deve variar de acordo com cada comunidade científica. Suponhamos a criação de um meta-dado para
descrever a seguinte frase:
a) “The author
of Document 1 is John Smith”
b) “John Smith
is the autor of Document 1”
Para interpretação
humana, as duas declarações possuem o mesmo significado,
mas para a máquina as duas declarações são “strings”
completamente diferentes. Então, quando desejamos criar um meta-dados para expressar os
autores de um documento,
como
devemos proceder para evitar este problema ? Suponhamos o caso da descrição
de uma imagem: como podemos criar meta-dados para
descrevê-la ? O ideal seria utilizar um vocabulário comum à comunidade científica especializada em processamento de imagem, para
facilitar inclusive, a recuperação das
informações desse tipo. E quanto
as fórmulas matemáticas e químicas ? Existem outras comunidades preocupadas em criar um vocabulário próprio para a criação de meta-dados. A Chemical
Markup Language, [6] (Linguagem
de Marcação Química) é um exemplo de
linguagem padronizada pela “Chemical Community” que entre outras,
oferece suporte para representação de meta-dados. Como
existem diversas maneiras de descrever meta-dados,
consequentemente a procura ou a troca de informações
sobre determinado assunto, se torna prejudicada. A idéia da criação de um padrão, definido
mundialmente para descreve-los seria complexo de gerenciar devido às diversas
áreas do conhecimento humano e do grande volume de informação que a Web contém. Pensando nesse problema, o artigo propõe uma solução resultante de
consensos e experiências de várias comunidades sobre como prover uma
arquitetura robusta e flexível
para descrever meta-dados na Web. O Artigo está organizado como segue: Seção 2
apresenta o RDF (Resource Description Framework) e a solução para o problema de semântica, a seção 3 apresenta
o modelo formal do RDF e uma ferramenta de interpretação como
exemplo e a seção 4 apresenta
as considerações finais com algumas sugestões adicionais.
PALAVRAS CHAVES: Meta-dados, RDF, Resource
Description Framework.
Os projetos de pesquisas contém informações
complexas dos mais variados tipos como: textos, tabelas, imagens, fórmulas
matemáticas, fórmulas químicas, referências a programas, referências às
atividades e outras. Além disso eles fazem parte de uma estrutura hierárquica,
em forma de árvore, que compreendem respectivamente Programas, Projetos e
Atividades. As informações, da forma que eram armazenadas a mais de dez
ou vinte anos atrás, dificultavam a sua recuperação. Observe o documento da figura 1, mesmo
utilizando técnicas avançadas de processamento de imagem, como limiarizações, no intuito de tratar e recuperar o texto, ainda
assim, a informação de que este documento é uma “ficha
de avaliação de uma atividade do projeto de Uso Potencial do Solo” contendo nome da atividade, métodos e resultados
alcançados, satisfatórios ou não, deveriam ser evidenciados, para permitir uma
recuperação mais precisa.
Figura 1. Ficha
de avaliação de resultados do projeto “Uso Potencial do Solo”
O HTML é uma tecnologia de ponta e tem mudado o
mundo em que vivemos. O problema em publicar os projetos de pesquisa, gerando
documento no formato HTML, é que informações importantes são perdidas, no
momento em que os dados são convertidos para este formato. A utilização de
marcações “META” para evidenciar o título do
projeto, autor, resumo, palavras-chaves e depois indexa-los em um servidor Web,
facilitam e melhoram a recuperação das informações, mas no entanto, os dados
referentes as informações úteis de uso potencial, dos mais diversos elementos
que compõe o projeto não são preservados.
2. O RDF –
Resource Description FrameworkNossa
proposta
Uma tecnologia emergente,
capaz de lidar com essa complexidade da descrição de
meta-dados,os projetos d está no uso
de um Framework de Infra-estrutura, o RDF.s A infra-estrutura do RDF, possibilita
a interoperabilidade de meta-dados, através do uso de mecanismos que suportam convenções comuns de semântica, sintaxe e estrutura. O RDF não
estipula a semântica para cada comunidade descrever seus
recursos, mas provê habilidades para
estas comunidades descrever os recursos de acordo com suas necessidades. Recursos temRecursos têm propriedades
(atributos ou características).
RDF define recursos como qualquer objeto que está unicamente identificado por um Uniform Resource Identifier (URI), que poderá
ser um documento uma imagem, uma tabela etc... As propriedades associadas
com recursos são identificadaos por tipos de propriedades e tipos de propriedades
tem correspondentes valores. Tipos de propriedades expressam a relação de valores
associados com recursos. No RDF valores
podem ser atômicos (strings, números,
etc.) ou podem conter outros recursos com suas
propriedades particulares. A coleção
das propriedades que se refere ao mesmo recurso são chamadas de “description”. Voltando ao “Documento 1”
do problema exemplificado acima, podemos considerar a representação do “Documento 1” como recurso,
pois ele pode ser identificado com o URI. A, assim o
modelo de dados correspondente a
declaração “the
author of Document 1 is JJohn Smith” tem: um simples
recurso chamado Document 1, um tipo de propriedade author e
o correspondente valor John Smith. Para
distinguir características de um modelo de dados a especificação
do modelo do RDF representa as relações entre
recursos, propriedades e valores através de um grafos onde os nós (desenho oval)
representam os recursos, os arcos (setas) representam as propriedades e as palavras
entre aspas ou citadas representam
os valores das propriedades.

Figura 1
Se for
desejado adicionar mais alguma informação relativo a
“John Smith” como emaile-mail e afiliação, estaremos descrevendo propriedades referente ao “author”, que nesse caso passa a ser tratado como
recurso Figura 2.
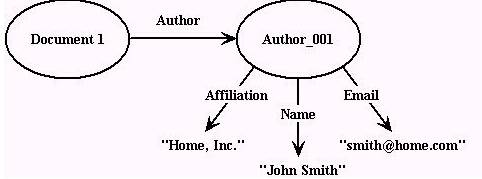
Figura 2
Neste caso o valor
“John Smith” é trocado por um único identificador de recurso denotado por “Author_001”
com as propriedades associadas: nome, e-mail e afiliação.
O modelo de
RDF permite a criação de recursos em múltiplos níveis. Adicionalmente
à representação de nomes
de pessoas, “John Smith”, poderia ter sido descrito, usando as
propriedades “nome” e “sobrenome”. Neste caso
o
detalhamento no processo de descrição pode se
estender por vários níveis, dependendo do domínio da aplicação. A solução proposta pelo
modelo de dados RDF, naturalmente soluciona o problema da semântica entre
as duas frases, restando como desafio dar, significado, para os
diferentes vocabulários das comunidades. Suponhamos a
propriedade “author”, dependendo
da necessidade de diferentes comunidades, ela pode
ter um significado mais amplo ou mais restrito. Como tal,, alguns problemas
podem esse problema pode
se agravaraparecer se múltiplas comunidades usarem as mesmas propriedades para dar
significado a coisas diferentes. Para prevenir isso, o RDF usa o mecanismo de “namespaces”[1], para evitar que
determinada propriedade tenha um sentido ambigüo. (mais de uma
interpretação). O mecanismo de namespaces pode ser criado por
qualquer comunidade que será a responsável pelo vocabulário (Schema)
do
seu domínio. Por exemplo, a propriedade “author” definida
por Dublin Core [2] definiu o
significado para a propriedade ““hautor como “An
entity primarily responsible for making the content of
the
resource.” e especificou um elemento chamado CREATOR para
identificar essa propriedade. Então utilizando o “Schema”
do Dublin Core abreviado como a sigla “DC”, o
exemplo da Figura 1
ficaria como segue:

Figura 3
Um caminho
para representar o meta-dado, utilizando o vocabulário do
Dublin Core, seria usar a sintaxe XML namespaces [1] como segue:
<?xml:namespace ns =
"http://www.w3.org/RDF/RDF/" prefix ="RDF" ?>
<?xml:namespace ns = "http://purl.oclc.org/DC/" prefix = "DC"
?>
<RDF:RDF>
<RDF:Description
RDF:HREF = "http://uri-of-Document-1">
<DC:Creator>John
Smith</DC:Creator>
</RDF:Description>
</RDF:RDF>
No RDF o
significado é expressado por um “schema”. Podemos pensar num eschema como um tipo de
dicionário. Um esquema define os termos
que serão usados nas declarações de
RDF e dá significado específico a eles. [8] Um esquema é um
lugar onde as definições e restrições do uso de propriedades são documentadas no
sentido de evitar confusões e conflitos de
definições do mesmo termo. No RDF cada predicado usado na declaração deve ser
identificado com exatamente um namespace. Entretanto, uma
descrição pode conter
declarações com propriedades de muitos namespaces. Mecanismos para
decrever valores complexos
também estão disponíveis. A sintaxe do RDF,
permite que outras propriedades possam ser valores de
propriedades. O exemplo abaixo mostra uma parte da sintaxe do qual a propriedade <DC:CREATOR>
mostrada nos exemplos acima, foi expressa
com outras propriedades de um namespace diferente. Neste caso o “vCard metadata schema” [3], que foi usado
para dar mais informação sobre o criador
“CREATOR” do recurso.
|
... <DC:Creator
parseType="Resource"> <vCard:FN> Dr Jacky J
Crystal </vCard:FN> <vCard:TITLE>
Director </vCard:TITLE> <vCard:EMAIL>
[email protected]</vCard:EMAIL> <vCard:ROLE>
Researcher </vCard:ROLE> </DC:Creator> ... |
Figura 4 – Valores
Complexos
RDF pode expressar
coleções das mesmas propriedades com Bags (Bag),
Sequences (Seq) e Alternatives (Alt). [4] Um RDF Bag é
simplesmente uma coleção de múltiplos valores para uma mesma propriedade.
O exemplo abaixo mostra três criadores de um recurso utilizando o container
(Bag). (Bag é usado quando a ordem da lista não é
importante).
|
... <DC:Creator> <Bag> <li> Maddie Azzurii </li> <li> Corky Brown </li> <li> Jacky Crystal </li> </Bag> </DC:Creator> ... |
Figura 5 – RDF Bag
Um RDF
Sequence (Seq) é uma coleção de múltiplos valores para uma propriedade onde a ordem
dos valores é importante. O exemplo abaixo mostra uma lista de três
criadores para um recurso, ordenados alfabeticamente
por
sobrenome.
|
... <DC:Creator> <Seq> <li> Maddie Azzurii </li> <li> Corky Brown </li> <li> Jacky Crystal </li> </Seq> </DC:Creator> ... |
Figura 6 – RDF -
Sequence
Um RDF
Alternative (Alt) é usado quando existe uma escolha de valores
disponíveis para uma propriedade, com cada valor válido, mas
dependente de algum outro fator. O primeiro
valor é considerado o “default”. O exemplo abaixo
apresenta uma lista com três possíveis locais para FTP de um mesmo
arquivo:
|
... <SOFT:Location> <Alt> <li>
ftp://soft-sales.com.us/abc.exe </li> <li>
ftp://soft-sales.com.au/abc.exe </li> <li>
ftp://soft-sales.com.de/abc.exe </li> <li>
ftp://soft-sales.com.uk/abc.exe </li> </Alt> </SOFT:Location> ... |
Figura 7 – RDF Alternative
3. O modelo formal
do RDF
Formalmente o modelo de
dados do RDF é representado com uma 3-tuples (triples) {pred, sub, obj} onde predicado (pred) é uma
propriedade, assunto (subject) é um recurso e objeto (obj)
ou é um recurso ou um literal. Utilizando a sintaxe formal do modelo RDF para
descrever meta-dados, as possibilidades de descrever
conteúdos “compreensíveis por
máquina” e a representação de conhecimento se tornam
enormes. Uma série de ferramentas estão sendo desenvolvidas para
validação e interpretação de meta-dados
que utilizam o modelo do RDF. O SiRPAC é um conjunto
de classes de Java que pode analisar documentos RDF/XML em 3-tuples de um
correspondente modelo de dados RDF. [7] O analisador
também pode ser configurado para buscar automaticamente o correspondente “schema” RDF do “namespace”
declarado. Para oferecer uma visão mais
detalhada da análise do modelo de RDF pela ferramenta, suponhamos o
exemplo abaixo:
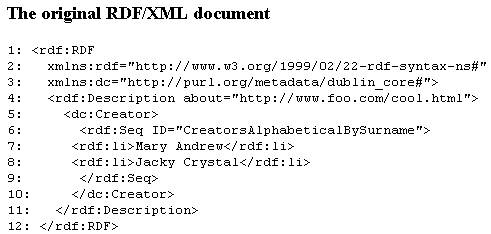
Figura 8 – Documento RDF
original
O modelo
original, figura 8, descreve em formato RDF dois criadores para a página “cool.html”. Segundo o modelo formal do RDF {pred, sub,
obj} a ferramenta retorna um conjunto de “triples” (recurso,
propriedades e valores) permitindo mais
facilmente a recuperação de propriedades
e o correspondente significado.

Figura 9 – 3-tuples
Analisando-se cada “3-tuples”
verificamos que o recurso “cool.html” foi descrito com outro
recurso do tipo “Seq”. (segundo a sintaxe do RDF). O recurso
“Seq” por sua vez, descreve dois valores em sequência. Finalmente para visualizar as “triples” na forma de gráfico, basta desenhar cada uma delas utilizando-se
do modelo gráfico formal do RDF onde:
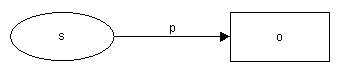
Figura 10 – Modelo
gráfico para declarações
S – descreve
o recurso;
P – descreve
as propriedades
O – descreve
o objeto.
Olhando para a figura
11, gerada pela
ferramenta SiRPAC podemos entender claramente que o recurso “cool.html”
possui dois criadores, estando eles, dispostos em sequência alfabetica
por sobrenome, onde o primeiro (_1) é “Mary Andrew”
e o segundo (_2) é “Jacky Crystal”.
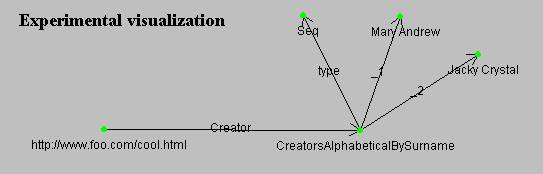
Figura 11 – Gráfico Rotulado gerado pela
ferramenta SiRPAC
4. Conclusão
Nesse sentido
o
modelo RDF, soluciona o
problema de semântica entre as comunidades, permitindo a criação de
propriedades e seus respectivos significados. Além disso, um modelo pode ser criado
para leitura humana e também para processos de computador, possibilitando
às aplicações
“aprenderem” com o esquema e validarem seus conteúdos. e pesquisa está no uso de linguagens de marcação
livre, como a XML (eXtensible Markup Language).
Diferentemente da HTML, na XML uma quantidade arbitraria de marcações podem ser
criadas, de forma que estas marcações evidenciem cada elemento que compõe o
projeto de pesquisa, inclusive a nível de tipos de elementos como, fórmulas,
variáveis, constantes, números, textos, e outras. Outra vantagem do uso de XML está na
flexibilidade de sua estrutura lógica. Um elemento de um projeto, como uma
tabela, pode ser criado fisicamente como uma entidade separada, e então, fazer
parte da estrutura lógica de vários projetos. Note que estamos falando de conteúdo e não de aparência de projetos
de pesquisa, pois na XML podemos exibir um mesmo conteúdo de diversas
maneiras. Mas a grande vantagem e a idéia principal desta proposta está
na reutilização e processamento dos
elementos que compõe um projeto. O ideal seria que, ao visualizar uma fórmula
matemática no texto de um projeto, pudéssemos interagir com essa fórmula,
executando, visualizando seus resultados ou até mesmo fazendo simulações com a
troca de valores das variáveis. Linguagens de marcações padronizadas para esta
finalidade estão sendo projetadas e já são realidade. A Chemical
Markup Language, (Linguagem
de Marcação Química) e a Mathematical Markup Language, Linguagem de Marcação Matemática, são exemplos de
linguagens padronizadas. Ferramentas e applets de navegadores estão surgindo
com a finalidade de dar vida aos elementos que compõe qualquer documento.
Quando uma fórmula matemática é escrita em Mathematical Markup Language ao invés de texto tradicional (com caracteres
especiais), elas podem ser submetidas às ferramentas especialmente feitas para
interpretar e executar esta linguagem, possibilitando simulações e validações de duas
maneiras: primeiro como uma caixa
preta, apenas utilizando a fórmula, e depois se necessário ou conveniente,
visualizando os detalhes de como ela foi construída. Para finalizar o conceito,
nossa proposta consiste em escrever num primeiro momento, cada elemento do
conteúdo de um projeto de pesquisa com marcações apropriadas àquele elemento, e
então, adicionar cada um deles (ou referências a eles), em uma estrutura lógica
maior, de marcação livre, formando o projeto de pesquisa como um todo. Um dos
detalhes importantes para esta implementação está na elaboração de uma
hierarquia de marcações. Essa hierarquia é importante para que árvore Programa, Projeto e Atividade de
pesquisa seja mantida. Isso pode ser conseguido através da análise de um
programa de pesquisa, com vários projetos com várias atividades. Com estas
marcações definidas, recursos adicionais da tecnologia XML, como as DTD’s –
Document Type Definitions podem ser
aplicados. Uma DTD vai garantir que os documentos XML dos projetos de pesquisa,
sejam elaborados com a hierarquia correta. O documento XML abaixo, foi
elaborado com base no documento da Figura 1. Note que as
marcações são livres, mas aninhadas, formando o chamando, “Documento XML de boa
formação”.
As marcações de início e final de cada elemento,
permitem que o seu conteúdo seja recuperado de forma segura, pois já é conhecido qual o tipo de informação que ele contém. O
aninhamento dos elementos do documento XML faz com que a informação “ficha de
avaliação de uma atividade do projeto de Uso Potencial do Solo” seja naturalmente mantida, o que não é evidente
em um documento no formato de imagem, texto simples ou HTML. Se o mesmo
documento fosse publicado em HTML a hierarquia de elementos estaria perdida
porque o conjunto de marcações HTML é predefinido e apenas exibe o conteúdo de
suas marcações no browser. Em HTML não se poderia criar uma marcação
<PROJETO> ou <AVALIACAO> para evidenciar um conteúdo específico.
Num segundo momento, podemos utilizar ferramentas de indexação e recuperação
para documentos de marcações livres. Suponhamos o documento acima indexado com
o Xdex [8], note que o
elemento “nome” aparece dentro do
elemento “projeto” e dentro do
elemento “atividade”. Nesta
ferramenta, usando suas capacidades de índices, o usuário poderia procurar por
todos os documentos
NOME = ”Uso Potencial do Solo” ou realizar uma pesquisa mais específica,
adicionando detalhes no argumento de busca como: AVALIACAO\PROJETO\NOME = ”Uso
Potencial do Solo” ou ainda ATIVIDADE = ”Levantamento detalhado de Solos de
Cambara”. Neste último, o conteúdo
procurado não é referente a marcação “atividade”, mas a procura
será realizada entre as marcações “filho” de atividade.
Conclusão
Um propósito simplesmente além do publicarinformar, seria descrever conteúdos pensando que eles poderão ser
utilizados a nível mundial, e que muitas áreas do conhecimento
humano farão uso dele. Além disso, representar
conhecimento, com algum mecanismo de argumentação, permitem às pessoas tirarem conclusões
com maior segurança e naturalmente colabora para
a construção da “Web de Confiança”.
não somente publicar as informações referentes aos
projetos de pesquisa, mas torná-las
vivas, oferecendo um mecanismo de interação com elas. Com essa
interação, os pesquisadores podem validar elementos, reutilizar, abstrair novas
idéias e tirar conclusões com mais segurança. Além disso, utilizar uma
linguagem independente de plataforma, garante o intercâmbio de informações de
forma padronizada e ágil. Para uma instituição, que tem como propósito
informar, gerar tecnologias e produtos, a velocidade em adquirir informações e
conhecimento é um fator determinante. Para esta instituição, publicar o grande
volume de resultados de pesquisas com uma tecnologia emergente a nível mundial,
valoriza seu patrimônio, divulga a instituição, traz divisas e aumenta
potencialmente sua competitividade.
Bibliografia
[1] BRAY,
Tim, HOLLANDER, Dave, LAYMAN, Andrew. Name Spaces in XML. W3C Note, [January 19, 1998]. Consultado na
Internet em 10 de maio de 2000: http://www.w3.org/TR/1998/NOTE-xml-names-0119.html
[2] DUBLIN CORE METADATA INITIATIVE. Dublin Core Metadata Element Set, Version 1.1:
Reference Description. [July 2, 1999]. Consultado na Internet em 12 de
junho de 2000: http://purl.org/DC/documents/rec-dces-19990702.htm
[3] IANNELLA. R. (1999) Representing vCard v3.0 in RDF.[January 14,
1999] Consultado na Internet em 22 de maio
de 2000:
http://www.dstc.edu.au/Research/Projects/rdf/draft-iannella-vcard-rdf-00.txt
[4] IANNELLA.
R. An Idiot’s Guide to the
Resource Description Framework. [September 3, 1998]. Consultado
na Internet em 12 de Junho de 2000: http://archive.dstc.edu.au/RDU/reports/RDF-Idiot/
[5] MILLER, Eric. An Introduction to the Resource
Description Framework. D-Lib
Magazine. [May, 1998]. Consultado
na Internet em 23 de maio de 2000:
http://www.dlib.org/dlib/may98/miller/05miller.html
[6] MURRAY-RUST,
Peter. XML and the launch of Chemical Markup
Language (CML). Virtual School of Molecular Sciences,
University of Nottingham.
[February 4,
1998]. Consultado na Internet em 20 de março de 2000: Http://www.vei.co.uk/chemweb/library/lecture2/abstract2.html
[7] SAARELA,
Janne. SiRPAC
- Simple RDF Parser & Compiler,
W3C, latest
release V1.14. [May 21, 1999]. Consultado na
Internet em 23 de maio de 2000: http://www.w3.org/RDF/Implementations/SiRPAC/
[8] WORLD
WIDE WEB CONSORTIUM (W3C). Resource
Description Framework
(RDF)
Model and Syntax Specification. [February
22,
1999]. Consultado na
Internet
em 23 de maio de 2000: http://www.w3.org/TR/REC-rdf-syntax/
SHIN, Dongwook;
JANG, Hyuncheol; JIN Honglan. BUS: An
effective indexing and retrieval scheme in structured documents. Department of Computer Engineering – Chungnam
National University, korea. [Aug. 1, 1998] pp. 1.
LIGHT, Richard. Iniciando em
XML. São Paulo:
Makron Books, 1999. 79-89 p.
McGRATH, Sean. XML:
aplicações práticas. Rio de
janeiro: Campus, 1999. 368 p.
SEAB -
Secretaria de Estado da Agricultura e Abastecimento do Paraná. Universidade do Campo - o que é. Curitiba,
PR. Disponível: http://celepar6.pr.gov.br/ucampo/ [capturado
em 15 mar. 2000].
MURRAY-RUST,
Peter. XML and the launch of Chemical Markup Language
(CML). Virtual School
of Molecular Sciences, University of Nottingham. [February 4, 1998]. Disponível: Http://www.vei.co.uk/chemweb/library/lecture2/abstract2.html
[capturado em
15 mar. 2000].
BUSWELL,
Stephen, DEVITT, Stan et. al. Mathematical Markup
Language
(MathML™) 1.01 Specification. W3C
Recommendation. [Jul, 7 1999]. Disponível: http://www.w3.org/TR/REC-MathML [capturado em
20 mar. 2000].
EMBRAPA. Diretoria Executiva (Brasília, DF). Siger. Sistema de Informação Gerencial da Embrapa. Manual do usuário. Brasília, 1999. 146p.
Sequoia Software Corporation. Introducing Xdex - Powerful XML Indexing Made Easy.
COLUMBIA, Md., [August 30, 1999]. Disponível: http://www.sequoiasoftware.com/pr_8_30_99_1.html [capturado
em 28 mar. 2000].